Professor Zhou Ligong’s hard work over several years resulted in two books: "Programming and Data Structures" and "Programming for the AMetal Framework and Interface (I)". Following the publication of these books, there was a surge of interest in the electronics industry. With Professor Zhou Ligong's authorization, this platform has begun serializing the content of "Programming and Data Structures" and is eager to share it with everyone.
The second chapter focuses on programming techniques, and today's article covers sections 2.1.1 "Function Pointers" and 2.1.2 "Pointer Functions."
>> >> >> > 2.1 Function Pointers and Pointer Functions
>> >> > 2.1.1 Function Pointers
A pointer to a variable points to a piece of data, and a pointer to another variable points to different data, enabling the retrieval of various information. Similarly, when a function is compiled, the system allocates memory for the corresponding code, and the starting address (or entry address) of this memory is essentially a pointer to the function. This allows the execution of a specific block of code at a particular address. A function pointer points to a segment of code (a function), and depending on which function it points to, the behavior of the program will vary.
Since the name of a function is a constant address, you can call the corresponding function by assigning the address of the function to the function pointer. Similar to how the name of an array represents the address of the array, the name of a function itself returns the address of the function. When a function name appears in an expression, the compiler automatically converts it into a pointer. This is akin to how an array variable name fetches its address implicitly. Therefore, the function name directly corresponds to the memory address of the function's instruction code, allowing the function name to be directly assigned to a function pointer. As the value of a function pointer can be modified, the same pointer can point to different functions. For instance:
```c
Int (*pf)(int);
```
What is the type of `pf`? K&R, the creators of the C language, explained this by stating: "Because * is a prefix operator, its precedence is lower than (). To ensure proper parsing, parentheses are necessary." While this explanation might seem logical, it can sometimes confuse people. The details are as follows:
```c
Int (*pf)(int a); // pf is a pointer to a function that takes an int argument.
```
That is, `pf` is a pointer to a function that returns an integer and takes an integer as its argument. The type "int(*)(int)" can be interpreted as a pointer to a function that returns an integer (with an integer parameter). You can also use `typedef` before defining the function pointer:
```c
Typedef int (*PF)(int a);
```
Before using `typedef`, `pf` is a function pointer variable; after using `typedef`, `pf` becomes a type for a function pointer. It is customary to name the type `PF`. For example:
```c
Typedef int (*PF)(int a);
```
Unlike other types of declarations, the declaration of a function pointer requires the use of the `typedef` keyword. Additionally, the only difference between the declaration of a function pointer and a function prototype is that the function name is replaced by `(*PF)`, where `*` means "a function pointer of type PF." Clearly, function pointer variables `pf1` and `pf2` can be defined with the `PF` type. For example:
```c
PF pf1, pf2;
```
This is equivalent to:
```c
Int (*pf1)(int a);
Int (*pf2)(int a);
```
However, this type of writing is harder to understand. Since a function pointer variable is just that—a variable—its value can be changed, allowing the same function pointer variable to point to different functions. Using function pointers involves the following steps:
1. Obtain the address of the function, such as `pf = add`, `pf = sub`.
2. Declare a function pointer, for example, `int (*pf)(int, int);`.
3. Use function pointers to call functions, such as `pf(5, 8)` or `(*pf)(5, 8)`.
Why is `pf` equivalent to `(*pf)`?
One argument is that since `pf` is a function pointer, assuming it points to the `add()` function, `*pf` is the function `add`, so the function is called with `(*pf)()`. Although this format might not look aesthetically pleasing, it provides a strong indication—this code is calling a function using a function pointer.
Another perspective is that since the function name is a pointer to a function, the pointer to the function should behave similarly to the function name, so `pf()` is used to call the function. This method is simpler and more elegant, making it the preferred choice—human nature gravitates towards simplicity and elegance.
While these explanations may seem contradictory, different contexts have different perspectives, and the tolerance for unspoken logical ideas is a hallmark of human thought processes.
Consider a pocket calculator that needs to perform various operations such as addition, subtraction, multiplication, and division. Even though the calling method remains the same, during the operation, it is necessary to decide which algorithm-supporting function to call based on the specific scenario. If the direct invocation method shown in Figure 2.1(a) is used, it inevitably creates a dependency structure. Any changes in the details will affect the strategy. By using the function pointer interface as shown in Figure 2.1(b), the dependency structure is inverted. When this structure is built, the details and strategies depend on the function pointer interface, thereby disconnecting unwanted direct dependencies.
When the abstraction is transformed into a function pointer, it inverts (or reverses) the dependency relationship. The high-level module no longer depends on the low-level module. Instead, high-level modules rely on abstraction, specifically an interface in the form of a function pointer, while the details depend on abstraction. `pf()` implements this interface, meaning both depend on the function pointer interface. In C, function pointers are typically used to implement Dependency Inversion Principle (DIP) and disconnect unwanted direct dependencies. Services can be invoked via function pointers (called code), and services can also call back user functions through function pointers. The principle remains the same, but during operation, it is necessary to decide which algorithm-supporting function to call based on the specific scenario. If the direct invocation method shown in Figure 2.1(a) is used, it inevitably creates a dependency structure. Any changes in the details will affect the strategy. By using the function pointer interface as shown in Figure 2.1(b), the dependency structure is inverted. When this structure is built, the details and strategies depend on the function pointer interface, thereby disconnecting unwanted direct dependencies.
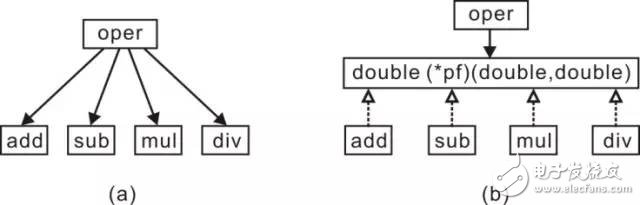
Function pointers are a powerful language feature that programmers often overlook. They not only make the code more flexible and maintainable but also help eliminate duplicate conditional logic. They also save the caller from having to compile or link a specific function, offering the significant advantage of reducing coupling between C language modules. However, the use of function pointers is conditional. If the calling relationship between the calling function and the called function never changes, the direct calling method is the simplest. In this case, the coupling between modules is reasonable, resulting in simple and straightforward code with minimal overhead. If you need to call a function with one or more function pointers at runtime, using function pointers is the best choice, typically referred to as a dynamic interface. A sample program is detailed in Listing 2.1.
Program Listing 2.1: Example Program for Calling Functions via Function Pointers (1)
```c
#include
int add(int a, int b)
{
printf("addition function");
return a + b;
}
int sub(int a, int b)
{
printf("subtraction function");
return a - b;
}
int main(void)
{
int (*pf)(int, int);
pf = add;
printf("addition result:%d\n", pf(5, 8));
pf = sub;
printf("subtraction result:%d\n", pf(8, 5));
return 0;
}
```
Since any data type pointer can assign a value to a `void` pointer variable, and the essence of a function pointer is an address, you can use this feature to define `pf` as a `void *` type pointer. Then, any pointer can be assigned to a `void *` type pointer variable. Its calling method is as follows:
```c
Void * pf = add;
printf("addition result:%d", ((int (*)(int, int)) pf)(5, 8));
```
During the use of the function pointer, the value of the pointer indicates the address that the program will jump to, and the type of the pointer indicates how the program is called. When calling a function with a function pointer, it is crucial to ensure that the type of the function being called matches exactly with the type of the function pointed to. Therefore, the `void *` type must be converted to `((int (*)(int, int)) pf)`, where the type is "int (*)(int, int)."
>> >> >> > 2.1.2 Pointer Functions
In fact, pointer variables are very versatile. Pointers can not only serve as arguments to functions but can also act as return values for functions. When the return value of a function is a pointer, the function is referred to as a pointer function. Given two integers, the function shown in Listing 2.2 returns a pointer to the larger of the two integers. When `max` is called, a pointer to two `int` type variables is used as a parameter, and the result is stored in a pointer variable, where the pointer returned by the `max` function is one of the two pointers passed in as arguments.
Program List 2.2: Find the Maximum Function (the Return Value is a Pointer)
```c
#include
int *max(int *p1, int *p2)
{
if (*p1 > *p2)
return p1;
else
return p2;
}
int main(int argc, char *argv[])
{
int *p, a, b;
a = 1; b = 2;
p = max(&a, &b);
printf("%d\n", *p);
return 0;
}
```
Of course, the function can also return a string, which is essentially the address of the string. However, care must be taken to ensure the validity of the returned address. You can either return the address of a static string or allocate a string of memory on the heap and then return its address. Be cautious about returning the address of a local string because the memory may be overwritten by other stack frames.
Let’s consider the difference between a pointer function and a function pointer variable. If the following definitions are made:
```c
Int *pf(int *, int); // int *(int *, int) type
Int (*pf)(int, int); // int (*)(int, int) type
```
Although there is only one set of parentheses between the two, the meanings are quite different. The essence of a function pointer variable is a pointer variable that points to a function. On the other hand, the essence of a pointer function is a function that declares `pf` as a function that takes two arguments, one of which is `int *` and the other is `int`, with the return value being a pointer of type `int`.
In pointer functions, there is also a class of functions whose return value is a pointer to a function. For beginners, writing such a function statement is challenging, and seeing such a syntax can be confusing. For example, the following statement:
```c
Int (* Ff (int) )(int, int); // Ff is a function
Int (* ff (int) )(int, int); // Ff is a pointer function whose return value is a pointer
Int (* ff (int))(int, int); // The pointer points to a function
```
Such writing is indeed difficult to understand, leading some beginners to mistakenly believe that writing incomprehensible code demonstrates their expertise. In reality, the ability to write clear and understandable code is a measure of a skilled programmer. Using `typedef` simplifies things. `PF` becomes a function pointer type:
```c
Typedef int (*PF)(int, int);
```
With this type, the declaration of the above function becomes much simpler:
```c
PF ff(int);
```
The following uses Program Listing 2.3 as an example to illustrate the use of function pointers as function return values. When the user inputs 'd', 'x', and 'p', the maximum, minimum, and average values of the array are obtained.
Listing 2.3: Sample Program for Finding Maximum, Minimum, and Average
```c
#include
#include
double getMin(double *dbData, int iSize) // Find the minimum
{
double dbMin;
assert((dbData != NULL) && (iSize > 0));
dbMin = dbData[0];
for (int i = 1; i < iSize; i++) {
if (dbMin > dbData[i]) {
dbMin = dbData[i];
}
}
return dbMin;
}
double getMax(double *dbData, int iSize) // Find the maximum
{
double dbMax;
assert((dbData != NULL) && (iSize > 0));
dbMax = dbData[0];
for (int i = 1; i < iSize; i++) {
if (dbMax < dbData[i]) {
dbMax = dbData[i];
}
}
return dbMax;
}
double getAverage(double *dbData, int iSize) // Calculate the average
{
double dbSum = 0;
assert((dbData != NULL) && (iSize > 0));
for (int i = 0; i < iSize; i++) {
dbSum += dbData[i];
}
return dbSum / iSize;
}
double unKnown(double *dbData, int iSize) // Unknown algorithm
{
return 0;
}
typedef double (*PF)(double *dbData, int iSize); // Define function pointer type
PF getOperation(char c) // Get the operation pointer based on the character, return the function pointer
{
switch (c) {
case 'd':
return getMax;
case 'x':
return getMin;
case 'p':
return getAverage;
default:
return unKnown;
}
}
int main(void)
{
double dbData[] = {3.1415926, 1.4142, -0.5, 999, -313, 365};
int iSize = sizeof(dbData) / sizeof(dbData[0]);
char c;
printf("Please input the Operation:");
c = getchar();
PF pf = getOperation(c);
printf("result is %lf", pf(dbData, iSize));
return 0;
}
```
The first four functions implement the maximum, minimum, average, and an unknown algorithm, respectively. The return value obtained by `getOperation()` based on the input character is returned in the form of a function pointer. From `pf(dbData, iSize)`, it can be seen that the function is called through this pointer. Note that a pointer function can return a new memory address, the address of a global variable, or the address of a static variable, but cannot return the address of a local variable, because after the function ends, the scope of the declared local variable inside the function ends, and the memory will be automatically released. Clearly, accessing the data pointed to by this pointer in the calling function will produce unpredictable results.
If you want to learn more about embedded courses, please scan the QR code below and start learning now!

4G Ufi and 5G Ufi are two Wireless Router devices in mobile communication technology. All of them can provide wireless Internet connectivity, but the main difference is the network technology and speed they support.
4G Ufi is a wireless router device that uses fourth-generation mobile communication technology (4G). It can connect to the Internet over a 4G network and provide network connectivity to other devices via Wi-Fi or wired connections. Key benefits of 4G Ufi include:
1. High-speed network connection: 4G Ufi can provide faster network speed than the traditional 3G network, which can meet the needs of users for high-speed Internet. This is important for applications with high bandwidth requirements such as online video, games, and downloading large files.
2. Stable connection: 4G Ufi uses 4G network connection, which provides a more stable and reliable connection compared to 3G network. This means users can better enjoy a seamless web experience, whether at home or on the move.
3. Mobility: Since 4G Ufi uses a wireless connection, users can use it anytime, anywhere. This is very convenient for people who need to use the network in different locations, such as travelers, business people, and students.
5G Ufi is a wireless router device that uses fifth-generation mobile communication technology (5G). It can connect to the Internet via 5G networks and offer faster speeds and lower latency. Key benefits of 5G Ufi include:
1. Extremely high Internet speed: 5G Ufi can provide higher Internet speed than 4G networks. According to the specifications of 5G technology, its theoretical peak speed can reach hundreds of megabits per second or even higher. This allows users to download and upload files faster, watch HD videos smoothly, and enjoy a faster Internet experience.
2. Low latency: 5G Ufi can provide lower latency than 4G networks. Latency refers to the time interval between sending and receiving data and is important for real-time applications such as online games, video calls and iot devices. Low latency provides faster response times and a better user experience.
3. Large capacity: 5G Ufi can support more device connections. Due to the high speed and low latency of 5G networks, it can connect more devices at the same time without degrading network performance. This is useful for scenarios where multiple devices need to be connected, such as homes, offices, and public places.
In summary, 4G Ufi and 5G Ufi are both wireless router devices, and the main difference between them is the supported mobile communication technology and speed. 4G Ufi provides high-speed, stable and mobile network connections, while 5G Ufi provides higher network speeds, low latency and large-capacity connections. Which device you choose depends on the user's specific requirements for network performance and requirements.
4G Ufi is a wireless router device that uses fourth-generation mobile communication technology (4G). It can connect to the Internet over a 4G network and provide network connectivity to other devices via Wi-Fi or wired connections. Key benefits of 4G Ufi include:
1. High-speed network connection: 4G Ufi can provide faster network speed than the traditional 3G network, which can meet the needs of users for high-speed Internet. This is important for applications with high bandwidth requirements such as online video, games, and downloading large files.
2. Stable connection: 4G Ufi uses 4G network connection, which provides a more stable and reliable connection compared to 3G network. This means users can better enjoy a seamless web experience, whether at home or on the move.
3. Mobility: Since 4G Ufi uses a wireless connection, users can use it anytime, anywhere. This is very convenient for people who need to use the network in different locations, such as travelers, business people, and students.
5G Ufi is a wireless router device that uses fifth-generation mobile communication technology (5G). It can connect to the Internet via 5G networks and offer faster speeds and lower latency. Key benefits of 5G Ufi include:
1. Extremely high Internet speed: 5G Ufi can provide higher Internet speed than 4G networks. According to the specifications of 5G technology, its theoretical peak speed can reach hundreds of megabits per second or even higher. This allows users to download and upload files faster, watch HD videos smoothly, and enjoy a faster Internet experience.
2. Low latency: 5G Ufi can provide lower latency than 4G networks. Latency refers to the time interval between sending and receiving data and is important for real-time applications such as online games, video calls and iot devices. Low latency provides faster response times and a better user experience.
3. Large capacity: 5G Ufi can support more device connections. Due to the high speed and low latency of 5G networks, it can connect more devices at the same time without degrading network performance. This is useful for scenarios where multiple devices need to be connected, such as homes, offices, and public places.
In summary, 4G Ufi and 5G Ufi are both wireless router devices, and the main difference between them is the supported mobile communication technology and speed. 4G Ufi provides high-speed, stable and mobile network connections, while 5G Ufi provides higher network speeds, low latency and large-capacity connections. Which device you choose depends on the user's specific requirements for network performance and requirements.
4G UFI,4G UFI oem,best 4G UFI,cheapest 4G UFI,4g ufi oem
Shenzhen MovingComm Technology Co., Ltd. , https://www.movingcommtech.com