Editor's note: OpenAI research engineers Vicki Cheung, Jonas Schneider, Ilya Sutskever, and Greg Brockman share in this article the infrastructure (software, hardware, configuration, and compilation) required to perform Deep Learning research and illustrate how to use the open source Kubernetes- Ec2-autoscaler automatically extends the network model in deep learning studies and will help a large number of deep learning research enthusiasts to build their own deep learning infrastructure.
Deep learning is an empirical science. The infrastructure construction of a research team will have a major impact on future research work. Fortunately, today's open source ecosystem enables anyone to have the ability to build a more sophisticated deep learning infrastructure.
In this article, we will introduce how deep learning studies are usually conducted, describe our choice of infrastructure to support deep learning studies, and open source Kubernetes-ec2-autoscaler, a batch optimization extension for Kubernetes. Manager. We hope that this article will help you build your own deep learning infrastructure.
Example
The development of deep learning usually comes from an idea that you use a small problem to test the feasibility of the idea. At this stage, you want to quickly carry out many ad hoc experiments. Ideally, you only need to use SSH (Shell Security Protocol) to connect a computer and write script code on the screen. Through this operation, the results are obtained. The entire research process takes less than one hour.
To make the model really useful, you will often experience many failures, and then find a feasible solution to overcome the limitations of the model itself. (This process is similar to building a new type of software system at will. You need to run your own code repeatedly so that you can imagine what they will produce later).

You need to examine your own models from multiple angles to see how these models actually learn. Dario Amodei's reinforcement learning agent (controlling the right racquet) scores higher in table tennis matches, but when you observe how it plays, you will find that the right racquet stays in place and does not move. Therefore, the deep learning infrastructure must be able to allow users to flexibly look back at the model used, and it is not enough to show only summary statistics.
When your model has a broad application prospect, you will want to extend it to larger data sets and higher resolution GPUs. This will be a long-term task. It will take many rounds of testing and it will last for many days. In the process of expanding the application, it is necessary to carefully manage the experimental process and carefully select the range of hyperparameter changes.
The early research process was not systematic, and the operation was quick. In contrast, the later research was carried out in an orderly manner. Although it was somewhat laborious, it was indispensable to obtain good experimental results.
Examples
At the beginning of the article, Improved Techniques for Training GANs, it was stated that Tim Salimans had designed several methods to improve the generation of confrontational network (GAN) training . We will describe these ideas here in the most simplified way (these ideas just produce the most beautiful sample, though not the best semi-supervised learning).
GANs consists of a generator network and a discriminator network. The generator tries to fool the discriminator, and the discriminator tries to distinguish between the generated data and the real data. Intuitively, we would think that a generator that can fool all discriminators must have good performance. However, there is still a difficult problem to overcome: always outputting almost the same (almost realistic) samples will cause the generator to "crash."
Tim made the following viewpoint, i.e. providing a small batch samples discriminator as input information, not just a sample. In this way, the discriminator can tell whether the generator always produces a single image. When the generator "crashes," the network will make gradient adjustments to the generator to correct this problem.
The next step will be to build prototypes based on the MNIST and CIFAR-10 perspectives. This requires that a small model be prototyped as quickly as possible, then the model prototype built should be run on real data, and the results obtained should be checked. After a few quick cycles, Tim captured the CIFAR-10 sample. This result is exciting and is the best sample we have seen in this data set.
However, deep learning (often called an AI algorithm) must be extended to really achieve impressive application results - a small neural network can be used to confirm a concept (or concept), but a large neural network Can be used to solve practical problems and get practical solutions. As a result, Ian Goodfellow has extended the model to focus on ImageNet.

Use our model to learn the generated ImageNet image
With a larger model and a larger data set, Ian needs to run the model in parallel on multiple GPUs. Each phase of the research process will increase the CPU and GPU utilization of multiple computers to 90%, but even this model will take many days to train. In the course of this research, each experiment conducted became very valuable. He will carefully record the results of each experiment.
infrastructure
software

Sample of our TensorFlow code
In our research, most of the code was written in Python, which we can learn a little from our open source project. Typically, we use the TensorFlow (in special cases, Theano) to calculate the GPU; use Numpy or other frameworks to calculate the CPU. Sometimes our researchers also use some frameworks that are better than TensorFlow to calculate GPUs or CPUs such as Keras.
Like many deep learning research teams, we use Python 2.7. Usually we use Anaconda, which can be easily packaged and optimized for performance, to handle difficult-to-package databases, such as OpenCV, and optimize the performance of some scientific databases.
hardware
For an ideal batch job, multiplying the number of nodes in the cluster by two will reduce the code run time by half. Unfortunately, in deep learning, sublinear acceleration phenomena are often observed in many GPUs. A high-performance model requires a top-level GPU. We also use most CPUs for emulators, enhanced learning environments, or small-scale models (on CPUs that run no faster than GPUs).
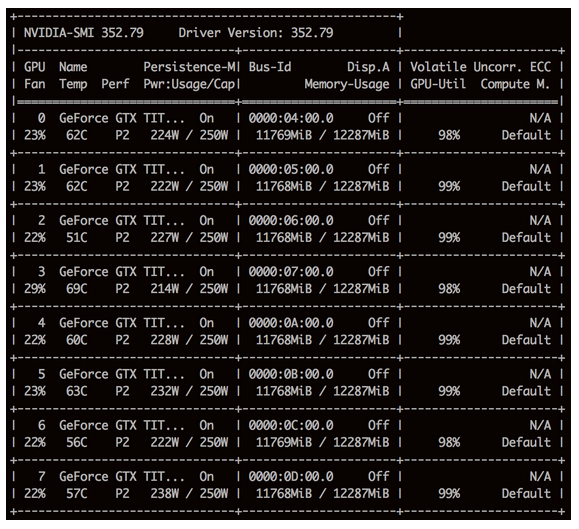
Titan Xs loaded with Nvidia-smi
AWS generously provided us with a large number of calculation methods. We are applying these calculation methods to the CPU instance and are used to scale the GPU horizontally. We also run our own server, mainly running Titan X GPUs. We hope to develop a hybrid cloud: It is extremely important to experiment with different GPUs, connections and other technologies, which will help the future development of deep learning research.
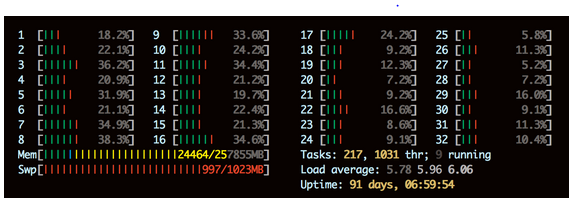
The same physical unit on htop shows many unoccupied CPUs. We usually run CPU-intensive work separately from GPU-intensive work.
Configuration
We treat the infrastructure of deep learning research just as many companies treat their own products: it must be able to present a simple interface, and availability and functionality are equally important. We use a set of interconnected tools to manage all the servers and make sure that each server is configured as much as possible.

Terraform configures fragment management auto-expanding groups. Terraform creates, adjusts, or destroys running cloud resources to match your configuration file.
We use Terraform to create AWS cloud resources (instances, network routes, DNS records, etc.). Our cloud and physical nodes are now running Ubuntu and configured with Chef. In order to achieve accelerated processing, we use Packe to preprocess AMI clusters. All of our clusters use non-overlapping IP ranges, using the OpenVPN on the user's laptop and the strongSwan on the physical node (used as the user portal for AWS) to connect to the public network.
We store users' home directories, data sets, and results on NFS (on physical hardware) and EFS/S3 (on AWS).
prepared by
The scalable infrastructure often makes the situation simple. We treat both small-scale work and large-scale work equally, investing in the same effort to build infrastructure. The toolkit is currently being actively expanded so that users can enjoy distributed use cases and local use cases at the same time.
We provide an SSH node cluster for ad hoc experiments and run Kubernetes as a cluster scheduler for physical nodes and AWS nodes. The cluster spans three AWS regions - our jobs are bursty and sometimes suddenly consume all the resources of some single region.
Kubernetes requires each job to be a Docker container , which provides us with dependency separation and code snapshots. However, building a new Docker container can add extra valuable time for the researchers to manipulate the code loop. Therefore, we also provide tools designed to transparently transfer the code on the researcher's laptop to a standard image.
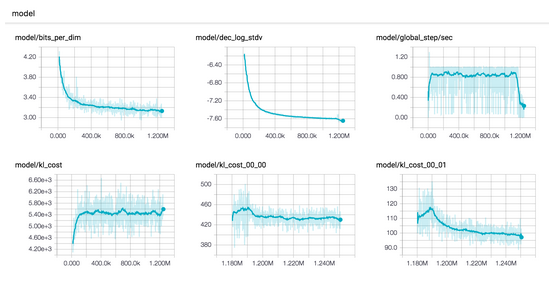
Build Learning Curve on TensorBoard
We applied Kubernetes' flannel network directly to the researcher's laptop, allowing users to use a seamless network to access researcher-run jobs. This is useful for accessing monitoring services such as TensorBoard. (The initial methodological requirements we adopted—faster and more error-free from a strict separation point of view—required people to provide a Kubernets service for the ports they wanted to expose, but we found that there were many problem).
Kubernetes-ec2-autoscaler
Our workload is sudden and unpredictable: a series of studies may quickly expand from a single computer experiment to 1,000. For example, in a few weeks, an experiment progressed from an interactive stage to running on a single Titan X, to 60 Titan X, and finally to nearly 1600 AWS GPUs. Therefore, our cloud infrastructure needs to dynamically configure Kubernetes nodes.
Kubernetes nodes can be easily run within an auto-expanding group, but it will be increasingly difficult to reasonably control the size of these auto-expanding groups. After the batch job is completed, the cluster will be able to accurately understand the resources it needs and can directly allocate these resources. (In sharp contrast, AWS's scaling strategy can accelerate each new node one by one until there are still remaining resources. This expansion process will continue for several cycles.) Therefore, before the cluster terminates these nodes, it needs to be released. Stream these nodes to avoid losing running jobs.
It is very tempting to use only the original EC2 for mass production. Indeed, this is also the starting point of our research work. However, the Kubernetes ecosystem brings greater value: low-resistance tools, logging, monitoring, and the ability to manage physical nodes away from running instances. It is easier to extend Kubernetes rationally than to rebuild the ecosystem based on the original EC2.
We are going to release Kubernetes-ec2-autoscaler, a batch optimization extension manager for Kubernetes. This manager can run on a conventional pod of Kubernetes, requiring only your work node to be within the auto-expand group.
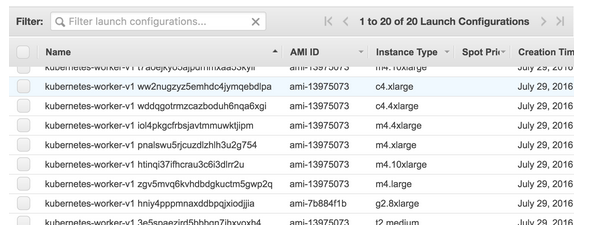
Kubernetes cluster startup configuration
The auto-expander works by gathering the state of the Kubernetes master node. The state of the master node includes all resources that need to be used to calculate cluster resource queries and capabilities. Under the condition that the available resources are excessive, the auto expander discharges related nodes and eventually terminates these nodes. If more resources are needed, the auto expander will calculate what type of server should be created, and appropriately scale up the auto-expansion group (or simply release the streamed node, which will reduce the cost of new node acceleration time).
Kubernetes-ec2-autoscaler can take care of multiple auto-expanding groups at the same time, enjoy resources (memory and GPU) outside the CPU, and can finely constrain the jobs you run, such as AWS region and instance size. In addition, because even AWS does not have unlimited memory, the bursty workload will cause the automatic expansion group to run over time and generate errors. In this case, Kubernetes-ec2-autoscaler can detect errors and allocate redundant jobs to the secondary AWS area.
Our infrastructure for deep learning is designed to maximize the efficiency of deep learning researchers and enable them to devote their time to research. We are building tools to further improve our infrastructure, improve our workflow, and share these tools in the coming weeks and months. Welcome everyone to work together to speed up the development of deep learning research!
Via Vicki Cheung et al
This article is compiled by Lei Feng Network (search "Lei Feng Network" public number) exclusive compilation, refused to reprint without permission!
universal dual USB car charger compatible with any Android and iOS mobile devices. Car charger adapter charges your mobile device at maximum charging speed your device supports. charge your mobile devices including the iPad (max speed), iPhone (max speed), iPod.
All of our product had 100% tested before delivery to FBA warehouse, include the car charger and the Cable compatibility with iPhone,iPad.
Charging will stop automatically when battery is full.to maximize the safety of your devices.
Car Mobile Charger,Car Charger,Double Car Charger,Dual Port Car Charger
Hebei Baisiwei Import&Export Trade Co., LTD. , https://www.baisiweicable.com